CDR Tickets
| Issue Number | 4875 |
|---|---|
| Summary | Add CDR IDs and filenames to audio pronunciation recording spreadsheet |
| Created | 2020-09-08 08:09:15 |
| Issue Type | Improvement |
| Submitted By | Osei-Poku, William (NIH/NCI) [C] |
| Assigned To | Kline, Bob (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2020-11-06 11:51:47 |
| Resolution | Fixed |
| Path | /home/bkline/backups/jira/ocecdr/issue.274282 |
Currently we manually enter the CDR IDs for documents that need to be re-recorded to the spreadsheet before sending it for audio recording. We want to look into the possibility of modifying the program that generates the audio recording spreadsheet so that those CDR IDs would be included when the spreadsheet is generated. This may mean modifying the glossary term name schema to add a new element/attribute indicating which terms need a new audio pronunciation recording. We'd also want to consider having the program add the filenames to the spreadsheet before sending the spreadsheet to Vanessa. If this is possible, I will provide you with a suggested way to name the files and also take into consideration your comment in ticket OCECDR-4863 about the naming convention that is used "..represent the current week".
I have modified this ticket to include one additional requirement (adding the filenames).
~oseipokuw: The title of this ticket doesn't make it clear which audio pronunciation recording spreadsheet it refers to. There's more than one. Because there's more than one ticket in Maxwell for the glossary pronunciation pipeline, and it seems likely there will be interdependencies among them, I'm going to lay out my understanding of the workflow sequence.
The Audio Request Spreadsheet command is invoked from the CIAT/OCC Staff admin menu. This command creates a new Excel workbook listing all of the glossary term names which still need a pronunciation MP3 file.
A zip file containing the workbook and an MP3 audio pronunciation file for each of the names on the spreadsheet generated by the previous step is created.
The zip file is posted to the SFTP server.
The Audio Import command is invoked from the CIAT/OCC Staff admin menu to pull the zip file down to the CDR server and queue up the MP3 files for review.
The Audio Review Glossary Term command is invoked from the CIAT/OCC Staff admin menu as many times as is needed until all of the MP3 files have been reviewed.
If any of the MP3 pronunciation files have been rejected, a followup workbook is generated with those rejections to get fresh replacement recordings from the contractor who generated the original pronunciation files.
When the files are ready to be imported, the Audio Import command is invoked from the CIAT/OCC Staff admin menu to create new Media files for the MP3s and link to them from the glossary name documents.
If I have left anything out or misrepresented the processing, please provide corrections. This list will be useful not just for this ticket, but also when we're figuring out what needs to be adjusted to use the ISO week numbering standard throughout the pipeline.
So, first question, which step(s) is this request referring to?
I have modified the steps to include additional details.
The Audio Request Spreadsheet command is invoked from the CIAT/OCC Staff admin menu. This command creates a new Excel workbook listing all of the glossary term names which still need a pronunciation MP3 file.
A zip file containing the workbook and an MP3 audio pronunciation file for each of the names on the spreadsheet generated by the previous step is created.
The zip file is posted to the SFTP server.
The Audio Download tool is invoked from the CIAT/OCC Staff admin menu to download the files for review.
The Audio Review Glossary Term command is invoked from the CIAT/OCC Staff admin menu as many times as is needed until all of the MP3 files have been reviewed.
The work is then saved. If any of the MP3 pronunciation files have been rejected, a follow-up workbook is generated with those rejections to get fresh replacement recordings from the contractor who generated the original pronunciation files.
Steps 3, 4, 5 and 6 are repeated until there are no more rejected pronunciations.
When the files are ready to be imported (completion of Step 7, no more rejected pronunciations), the Audio Import command is invoked from the CIAT/OCC Staff admin menu to create new Media files for the MP3s and link to them from the glossary name documents.
~oseipokuw: The title of this ticket doesn't make it clear which audio pronunciation recording spreadsheet it refers to.
It is the spreadsheet in Step 1 that this ticket refers to. However, it will also affect all the subsequent spreadsheets that are generated due to rejected pronunciations. In other words, all the spreadsheets should include the CDR IDs and filenames.
I propose adding an optional NeedsReplacementMedia="Yes"
attribute to the MediaLink element type. Will this be
suitable? I am speculating that this name would be more generally useful
than NeedsRerecording which would not be appropriate for
other types of media should the need arise to extend this principle.
My picture of what you are requesting is that we will be adding the CDR ID of the Media document to the Reuse Media ID column in the few cases where this new attribute is populated, whereas we will be populating the Filename column for all of the name rows in the spreadsheet. I am asking for confirmation of this understanding, as it seems unintuitive to couple the request for a special-purpose modification of a handful a cells with an unrelated request to populate another column for all of the rows. It's OK to leave these two requests in this single ticket, but it would be good to get acknowledgement and confirmation that this is what we're doing.
I believe all of the modifications for this ticket have been implemented and installed on DEV.
Note to myself: the deployment up the tiers requires a modification
to the term_audio_mp3 table to add the new
reuse_media_id column.
It looks like having the NeedsReplacementMedia="Yes" on
the MedialLink element in the GTN will create another problem. In order
for a document so show up on the spreadsheet for re-recording, we need
to remove the MediaLink (this change was done in Leibniz). So, for
re-recordings, we wouldn't have a MediaLink in the GTN. So, I think
having the attribute on Term Name element will be a good alternate
approach.
Have you tested to confirm this? I thought I had implemented this so
that the name got included on the spreadsheet if there was no
MediaLink element OR the MediaLink element had
the new attribute. And I thought I had tested that to confirm. Give me
an example of a term name which didn't work the way you expected (that
is, didn't show up on the spreadsheet).
bq. Have you tested to confirm this?
I haven't tested it yet. I was just reviewing the ticket. It will be great if we can test ticket the other OCECDR-4890 since it is really time consuming testing these.
Please explain why the way it's implemented would not work before we
change the requirements again. The way it's working now (unless I'm
mistaken) allows you to add the NeedsReplacementMedia
attribute to the MediaLink element to cause the name to be
added to the spreadsheet with the media document ID in the last column
on the spreadsheet. Isn't that what I proposed we do, and you
approved?
The first steps in the re-recording process are to update the term
name and pronunciation key as well as remove the MediaLink (because the
media will no longer match the updated name string and cause a mismatch
on Cancer.gov). Since the MediaLink is removed as part of the process,
having the new attribute NeedsReplacementMedia="Yes" on the
term name appears to be a better solution.
So if you remove the MediaLink element, where will I get
the ID of the Media document we're going to reuse from?
Would you be able to get it from a previous version of the document?
It would be more straightforward, and safer, to have the publishing export filter drop links which have been marked as needing replacement.
Sure. I will enter a ticket for the filter change.
Moving back to the Resolved column, since we are addressing the new requirement with another ticket.
Looking at this gain, it seems there is still one step that needs to be done in order for the re-recorded audio to be re-published to Cancer.gov (after the links habe been dropped (OCECDR-4911)). Or we may have to go into each of the re-recorded terms to remove the value for the NeedsReplacementMedia="Yes" attribute. The question is, would it be possible to remove the "Yes" attribute after re-recorded audio has been updated ?
Yes.
Great. Please proceed to implement this new requirement. Thanks!
I have implemented the new requirement, though it is actually more closely related to OCECDR-4890, which is where the media document is updated, rather than to this ticket, which has to do with generation of the spreadsheet.
Verified on DEV. Thanks!
Some terms we marked with the NeedsReplacementMedia="Yes" attribute are not showing up in the latest spreadsheet from QA. They are terms in the Translated Name section of the documents. We did not run into this problem on DEV. The terms in green font showed up in the spreadsheet but not the other terms. I have also attached the lates spreadsheet from QA. Week_2020_45_QA.xlsx
CDR ID:785269 - reproductive hormone
CDR ID: 798602 - lead shield
CDR ID 44959 – perfusion magnetic resonance imaging
CDR ID 44730 – social worker
CDR ID 689569 – diagnostic test
CDR ID 450097 – coping skills
796880 ALK positive
796946 ROS1 positive
CDR ID 737998 – HER2-positive cancer
CDR ID 767116- CAPIRI regimen
The glossary term name docs needed to be reindexed on QA. Please try again.
The glossary term name docs needed to be reindexed on QA. Please try again.
That worked. Thanks,
There seems to be a problem with the Audio Review Glossary Term report. When you click on the link in the menu, you get the attached error message.
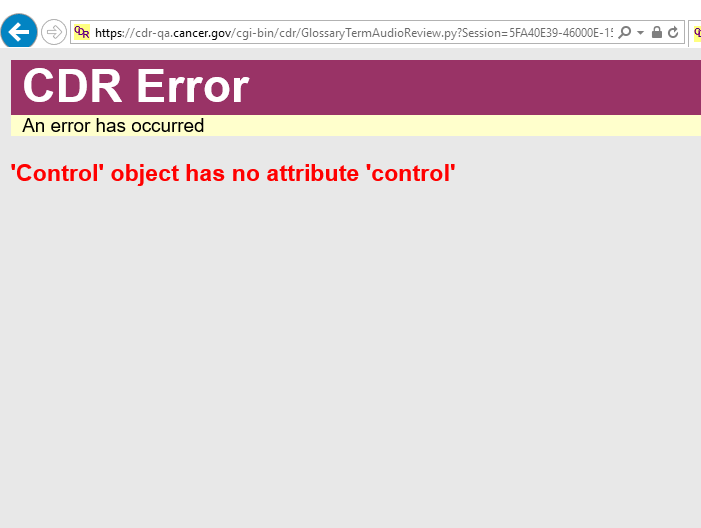
Fixed on DEV and QA.
I am getting this message. It looks like you may have to clear the old files from the sftp site. I still don't have write access to the folder.
An error has occurred
Found file 'Week_137.zip'.
Please correct the name to reflect one of the following formats or contact programming support staff for assistance.
Week_YYYY_WW.zip or Week_YYYY_WW_RevN.zip
... where 'Y', 'W', and 'N' represent decimal digits
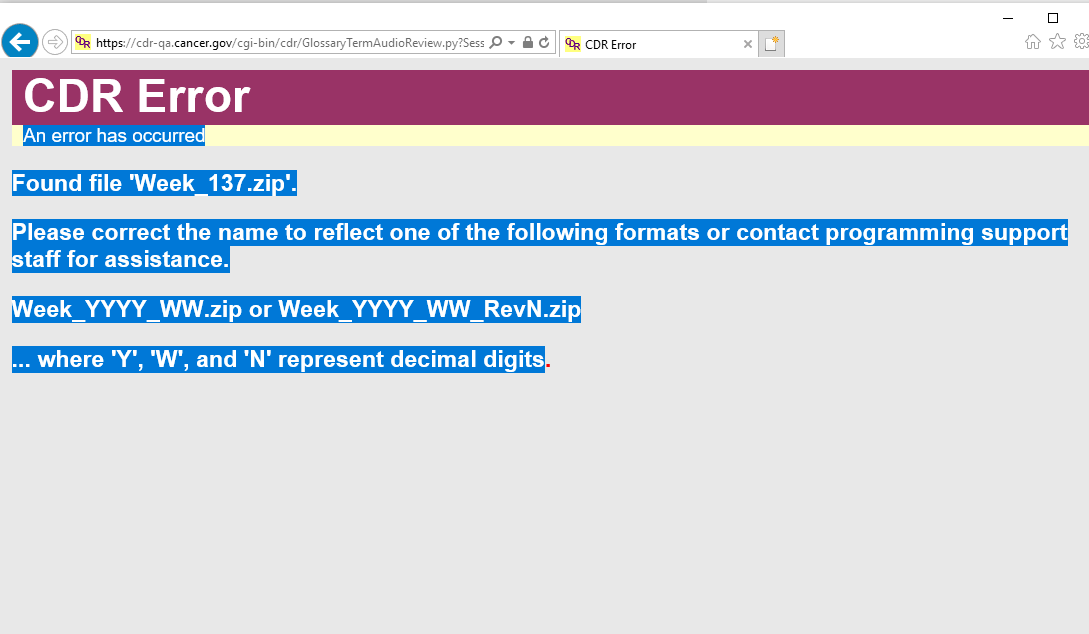
I have cleared out the files with the legacy naming patterns from both QA and STAGE.
I am still getting the same error message on QA this morning.
CDR Error
An error has occurred
Found file 'Week_137.zip'.
Please correct the name to reflect one of the following formats or contact programming support staff for assistance.
Week_YYYY_WW.zip or Week_YYYY_WW_RevN.zip
... where 'Y', 'W', and 'N' represent decimal digits.
Ah, well I cleared the legacy sets from the SFTP server as you had requested, but that's not where the problem lay. I had to add a custom rule to the file sweeper to speed up the archiving of the legacy sets which had leftover from incomplete testing on QA. I did the same on PROD, archiving the legacy sets there (you had said they were complete, and I confirmed that status in the database), so we won't have any problems when we deploy to production. STAGE didn't have any legacy sets. Please try again.
Yes, it is working now. Thank you!
Verified on QA. Thanks!
Verified on PROD. Thanks!
| File Name | Posted | User |
|---|---|---|
| audio_warning_error.PNG | 2020-11-05 19:42:25 | Osei-Poku, William (NIH/NCI) [C] |
| audio review report error.PNG | 2020-11-05 17:08:25 | Osei-Poku, William (NIH/NCI) [C] |
| Week_2020_45_QA.xlsx | 2020-11-05 10:26:38 | Osei-Poku, William (NIH/NCI) [C] |
Elapsed: 0:00:00.001314