CDR Tickets
| Issue Number | 4633 |
|---|---|
| Summary | [Glossary-Media] Re-use existing media docs |
| Created | 2019-06-19 22:12:03 |
| Issue Type | New Feature |
| Submitted By | Osei-Poku, William (NIH/NCI) [C] |
| Assigned To | Kline, Bob (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2020-06-11 16:48:16 |
| Resolution | Fixed |
| Path | /home/bkline/backups/jira/ocecdr/issue.245711 |
Since it would be possible now to have terms that are being re-recorded (OCECDR-4507) That is, terms that previously had audio pronunciation media docs but they have been removed from the terms because the terms have been revised. Our preference would be to re-use the existing media docs for the terms instead of creating new media docs (new version on top of existing media doc).
Comment in OCECDR-4507 from Bob:
"For the last request above (reuse of an existing media document), that happens in a different program, so you'll want to create a different ticket (added in Kepler). Since the audio link is no longer present, you'll need to come up with a way to specify the CDR ID of the existing document you want to use for the sound clip in the spreadsheet fed to that program"
Is it possible to get the CDR ID from a previous version of the document? If that is not possible, then we can probably record the CDR id in a new element before we delete the link.
I recommend putting the ID in the spreadsheet where the import is requested.
Sure. The CDR IDs should be present in the spreadsheet that is uploaded with the recorded files to the FTP site, right ?
Right. We'll need to agree on which column the software should look in to find the value.
I propose the following expected column positions for the audio spreadsheets:
column A - CDR ID for
TermNamedocument (required integer)column B - term name string to be pronounced (required)
column C - English or Spanish (required string)
column D - optional pronunciation string
column E - relative path name for MP3 file (required when import stage has been reached)
column F - notes from Vanessa (optional string)
column G - notes from NCI (optional string)
column H - CDR ID for
Mediadocument to be updated (optional integer)
Three questions:
Can we agree on this column positioning?
Should the import software abort if it encounters an ID in column H for a non-Media document?
Should the import software abort if an ID is given in column H for which no CDR document exists?
Column H in the current spreadsheet is labeled "Reuse Media ID". I assume what you're proposing is for the same use. If that is the case, can we retain "Reuse Media ID" ?
So you're suggesting that I find the CDR ID rather than have the spreadsheet provide it? If so, what would be the drawback to having the software always re-use the existing Media document's ID whenever it finds a media link for a given term name string? That way the new column wouldn't be needed at all.
The spreadsheet will still provide the CDR ID of the terms being re-recorded. I think we already agreed that CIAT will use the column to provide the CDR IDs of the terms that are being re-recorded. We had also agreed on what to name the column in this ticket OCECDR-4507.
"Bob will add a column to the spreadsheet with the heading "Reuse Media ID". This will be used to enter the media IDs for any pronunciations that are being re-recorded so that Bob doesn't create new media docs for them."
So my request is to get clarification on that and possibly keep the original column name.
I don't understand your question about the drawback since there wouldn't be a Media Link for the term as stated in the initial request above. The first step in the re-recording process is removing the media link and getting the term on the spreadsheet so if you can clarify what you want the software to do in terms of finding the media link, that would be great.
Since I hadn't said anything in this ticket about changing the column labels, I thought you were asking if the last column could be repurposed to take a yes/no flag indicating that we should "reuse the media ID" instead of just entering the ID. If that's not the case, and you're sticking with the original plan of stripping the link from the documents as the first step, then let's roll back to my 1:03pm Monday comment and its three questions:
Can we agree on this column positioning?
Should the import software abort if it encounters an ID in column H for a non-Media document?
Should the import software abort if an ID is given in column H for which no CDR document exists?
Yes to all 3 questions.
Enhancement (not sure why this was entered as a bug report, as I'm certain this was not part of the original requirements given to Alan) installed on DEV.
I have corrected this from a bug report to request for a new feature. Thanks!
On the Audio Review of Glossary Terms page, it looks like the Review
Note field has been populated by the CDR IDs of the Media Docs. We use
this field for a different purpose. 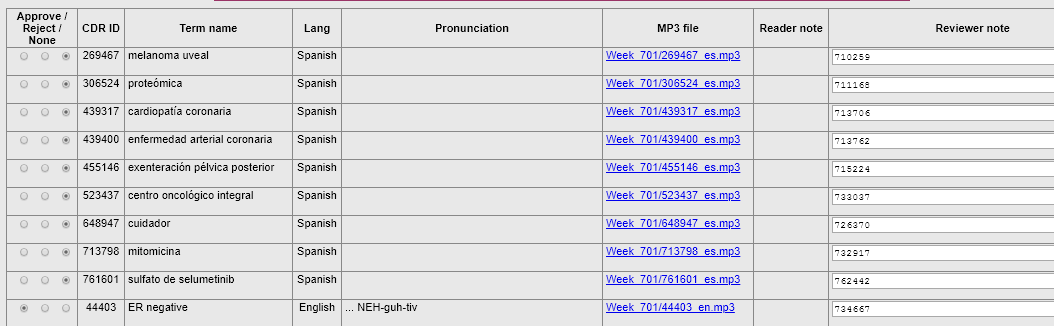
Aargh! Jira just threw away a very long comment in which I explained what caused this problem and how I fixed it.
TL;DR: it had to do with how the script handled variations in the structure of the spreadsheets. Should be OK now.
We've completed reviewing Week_701.zip and ready to import but when I run the Audio Import report, that file does not show up. Only Week_800.zip shows up even after submitting Week_800.zip, it continues to show up.
I'm pretty sure the requirements for the import script have always been to deal with the latest set ("week" — though that's something of a misnomer) only. So I believe the script is behaving the way it's supposed to. If you have found requirements docs which say otherwise, please let me know.
~volker Is it possible for you to remove the Week_800.zip file from the FTP or CDR server? Or it is too late now? Thanks!
I'm able to remove the file from the FTP server and I would be able to remove it from the CDR server if we're talking DEV or QA tier.
Which tier are you looking at? Is this for DEV?
This is on DEV. Thanks!
Removed from the CDR DEV server.
It worked. Thank you!
The import was successful. However, several terms were skipped (please see attached). I am not sure why they were skipped.

It skips over glossary docs which already have at least one media link.
The recording is for the other block within the same doc without the media link so it shouldn't be skipped.
The software has always prevented updating glossary docs which have any existing media links. I'll see how tricky it will be to modify that behavior.
This has taken long enough that I should have had you file another ticket to change that behavior in Maxwell, but I've already done the hard work, so let's just proceed. I have removed the code to block processing of glossary documents which already have any existing media links. What do you want the software to do if the spreadsheet asks to insert a media link for a name string block which already has one?
fail the job?
replace the old link?
add a second link (making the document invalid)?
don't do anything with the link?
That would be an error so the job should fail - #1.
Thank you!
OK, I have made the modification. Please test.
Verified on DEV. Thank you!
The files appear to have successfully downloaded on QA but we are not able to listen to the audio files on QA. The error message is "There is no item named 'Week_701/44403_en.mp3' in the archive" for each of the terms.
That's a data problem. Too many levels in the path for the files.
$ unzip -l Week_701.zip
Archive: Week_701.zip
Length Date Time Name
--------- ---------- ----- ----
0 2020-06-09 14:21 Week_701/Week_701/
33843 2020-04-30 18:19 Week_701/Week_701/269467_en.mp3
22942 2020-04-28 12:28 Week_701/Week_701/269467_es.mp3
19944 2020-04-30 08:28 Week_701/Week_701/306524_es.mp3
29776 2020-04-30 08:28 Week_701/Week_701/439317_es.mp3
38804 2020-04-30 08:28 Week_701/Week_701/439400_es.mp3
22199 2020-05-21 12:10 Week_701/Week_701/44386_en.mp3
26587 2020-06-09 11:09 Week_701/Week_701/44386_es.mp3
28757 2020-04-30 18:16 Week_701/Week_701/44403_en.mp3
29750 2020-04-30 18:16 Week_701/Week_701/44404_en.mp3
31080 2020-04-30 18:16 Week_701/Week_701/44449_en.mp3
28886 2020-04-30 18:16 Week_701/Week_701/44450_en.mp3
48530 2020-06-08 14:17 Week_701/Week_701/44985_en.mp3
21989 2020-06-09 11:09 Week_701/Week_701/44985_es.mp3
38173 2020-04-28 12:28 Week_701/Week_701/455146_es.mp3
52469 2020-04-30 18:16 Week_701/Week_701/471770_en.mp3
35776 2020-04-28 12:28 Week_701/Week_701/523437_es.mp3
30871 2020-04-30 18:16 Week_701/Week_701/642120_en.mp3
16548 2020-04-28 12:28 Week_701/Week_701/648947_es.mp3
25819 2020-04-30 18:18 Week_701/Week_701/713798_en.mp3
17127 2020-04-28 12:28 Week_701/Week_701/713798_es.mp3
40940 2020-04-30 18:18 Week_701/Week_701/761601_en.mp3
31313 2020-04-28 12:28 Week_701/Week_701/761601_es.mp3
52551 2020-04-30 18:15 Week_701/Week_701/793179_en.mp3
39193 2020-06-09 13:59 Week_701/Week_701/798756_es.mp3
28184 2020-06-09 13:59 Week_701/Week_701/798765_es.mp3
17952 2020-06-09 14:21 Week_701/Week_701/Week_701.xlsx
--------- -------
810003 27 files
We've fixed the problem and sent you a new zip file by email. Could you please remove the existing one and reload this new file? Thanks!
Done.
Unfortunately, we are getting the same error message.
"There is no item named 'Week_701/44403_en.mp3' in the archive"
I've put it up there again, and I confirmed that the directories have been fixed. Please try it one more time (and we'll hope the database doesn't have the old paths stuck somewhere).
It worked. Thank you!
The import job worked for the most part. However, audios were not linked to the following terms and that is because the program was interrupted by CDR648947 which already had a MediaLink (our error). We corrected this error by removing the MediaLink and then I ran the import job again. This created duplicates for some of the audio files, however, they were not linked to the remaining terms. So while the program works, when there is an error like the one above, and it is corrected, it doesn't look like I can re-run the program successfully.
713798
713798
761601
761601
798756
798765
Add a Maxwell ticket to handle that condition.
Okay. Will do.
Verified on QA. Thanks!
Week_702.zip is on the SFTP server.
Thanks! It worked. However, we can't figure out why the two terms below failed during import
CDR798756 unable to find home for 'análisis citogenético ' in
CDR798756
CDR798765 unable to find home for 'cateterismo cardíaco ' in
CDR798765
That's because 'análisis citogenético ' (note the extra space in the error message) doesn't match 'análisis citogenético' (same for the other term).
So, this is from the spreadsheet, right?
I see that it is from the spreadsheet. Thanks!
Verified on QA. Thanks!
yep
Still testing?
We have not been able to test this on PROD yet . I am closing the ticket now and will reopen if necessary.
| File Name | Posted | User |
|---|---|---|
| Audio Re-use DEV run.JPG | 2020-05-19 21:05:17 | Osei-Poku, William (NIH/NCI) [C] |
| GlossaryReviewPage_Dev.PNG | 2020-05-14 13:06:41 | Osei-Poku, William (NIH/NCI) [C] |
Elapsed: 0:00:00.001635