EBMS Tickets
| Issue Number | 711 |
|---|---|
| Summary | HTML tags displaying in citation title |
| Created | 2023-01-23 13:11:09 |
| Issue Type | Bug |
| Submitted By | Boggess, Cynthia (NIH/NCI) [C] |
| Assigned To | Kline, Bob (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2023-01-23 15:03:52 |
| Resolution | Fixed |
| Path | /home/bkline/backups/jira/oceebms/issue.336911 |
From the Librarian Queue, selected titles are displaying HTML tags.
To repro in EBMS4- go to the Librarian queue, enter %<%>% in the title field and filter. You should retrieve 39 citations.
For some citations, HTML tags only seem to be displaying in the queue. If you click on the title and go to the Full Article History, the title is displaying correctly. Also, when you search for the article using pmid on the Article Search page the title appears correctly in the retrieval list.
However, there are 147 citations in the database where the html tags are displaying in the Full Article History and in the retrieval list when searched from Article Search page.
To repro - go to the article search page and enter %<%>% in title field and click submit.
In Prod, this is happening as well. There aren't any in my queue at the moment, but a search of database using %<%>% in the title field retrieves 134 citations where 75 are from 2022. The remaining are a few for each year dating back to 2003.
And while investigating this, we noticed that in the Librarian Queue when using the Abstract display, words in italics were missing from the abstract. Luckily, this does not seem to be happening in EBSM4.
My initial assessment is that this is a duplicate of OCEEBMS-684, compounded by the impact of OCEEBMS-687. When I first noticed this problem, I reported it to NLM, and they said it's caused by flawed markup uploaded by the publishers. When NLM notices the problem, they alert the publishers, urging them to submit corrected markup. The contribution of OCEEBMS-687 to the problem is the fact that by failing to give us all of the PubMed IDs for articles which have changed when we run our scheduled refresh job, which is supposed to fetch corrected XML in this situation, we end up left with the flawed markup well after NLM has the fixed XML. I ran an experiment, using an import job to import PMID 34928524, the first article to show up using the search you described above, entering the same cycle, board, and topic. Because I had used the same values as the original import job, the only effect was to pull in the corrected XML from NLM and to record the replacement import. Does this explanation make sense to you? We're in negotiations with NLM to get them to cough up all of the PubMed IDs for the modified articles. We'll see how that goes. Neither of these problems is new with EBMS4, as you've noticed. 😛
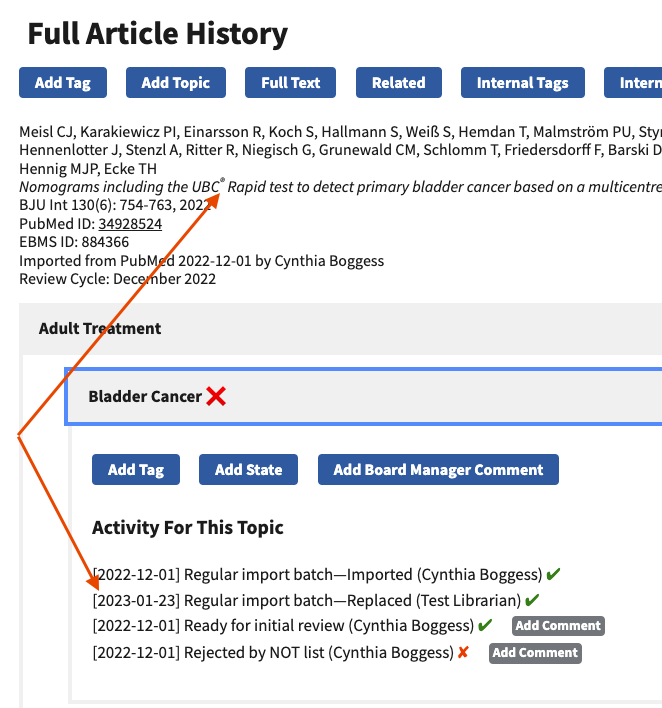
This might not be just a duplicate, as I may still have a problem in the review queue. Let me dig further.
Review queue on https://ebms.rksystems.com is now displaying the titles correctly, I believe.
When testing this on erc, I was expecting to get zero results when I filtered the librarian queue by %<%>% in the title field, but instead I retrieved 35 citations. However, after looking at all 35 of the titles, no html tags are displayed.
Should work correctly now. I had been using the title
field (which stores the HTML markup) for the filtering query, when I
should have been using the search_title field (which strips
out the HTML markup). Fixed now on https://ebms.rksystems.com.
There are still two cases in which filtering with
%<%>% will still match articles.
when the publishers submit XML with the markup inappropriately doubly-escaped (as described in my original comment on this ticket); and
when the
<and>characters appear not as part of markup tags, but as part of the text (for example, "... we found that with bilirubin levels > 1.1 mg/dL and < 1.2 mg/dL ...").
But those should be relatively rare. And even rarer when we convince NLM to alert us for ALL of the changed articles. 😃
Ok so now I am getting zero when I search %<%>% in the title field for the Librarian queue. And yes, good point < and > may appear in the title for other reasons.
But on the Article search page retrieval list, I'm still retrieving 120 when I search %<%>% in the title. Will the same change fix this list of citations as well? or are we going to have to wait on NLM?
The search page has always used the right field (the
search_title field). That (the fact that you see 120
articles with bogus markup in the titles) is a problem we're stuck with,
for the two reasons I gave earlier:
publishers give NLM flawed markup
NLM fails to notify us of all changes
The first problem is permanent (there will always be confused publishers who don't understand how XML markup is supposed to work. We're hoping the second problem is a short-term problem.
Let's look at the first hit for the 120 (assuming the sort order is by the EBMS ID). Here is what we got from NLM for the title when Jeff imported the article.
<ArticleTitle>Extracts of the Medicinal Plants <i>Pao Pereira</i> and <i>Rauwolfia vomitoria</i> Inhibit Ovarian Cancer Stem Cells <i>In Vitro</i>.</ArticleTitle>The reason we got that is because that's how the publisher gave it to NLM. Here's what the publisher should have provided (and they actually have, at this point in time, with a little nudge from NLM to fix the record):
<ArticleTitle>Extracts of the Medicinal Plants <i>Pao Pereira</i> and <i>Rauwolfia vomitoria</i> Inhibit Ovarian Cancer Stem Cells <i>In Vitro</i>.</ArticleTitle>A few years ago, NLM modified its XML structures so that titles (and abstracts) which, until then, had only allowed plain text without any markup, would now allow a small handful of inline markup elements for things like superscripts, subscripts, or bold or italic text. When a "<" or ">" character is intended to be part of the text itself, rather than a delimiter indicating when a new inline element begins or ends, it gets encoded so that XML parsers won't get confused. So "bilirubin levels < 1.2 mg/dL" would actually be stored as
bilirubin levels < 1.2 mg/dLand the systems displaying the text would know that
<represents the "<" character. So when we got the first version of the title above, we were being told that the title is Extracts of the Medicinal Plants <i>Pao ....
Again, once you have determined, for a specific article, that NLM has been given the corrected record by the publisher, then you can force the EBMS to pull it in by doing a "duplicate" import using the same topic as was used for the original import. But that's tedious to do for 120 articles (and of course, not all of the 120 will already have been fixed at NLM by the publishers).
As you can see from running the same search on the production EBMS, these problems are not unique to EBMS 4.
We will always have some titles (and abstracts) with bogus markup. We hope that we'll have significantly fewer such problems once we convince NLM to tell us when ALL of the changes to their articles happen. And we hope that day comes sooner, rather than later.
I hope this long-winded explanation helps, rather than obfuscates further. 😛
Thanks Bob, for taking the time to explain this in detail. I think overall to have only 150 or so in the database is not so bad especially knowing that only a small percentage of these will end up in a packet sent to the board members. And in the event one is included in a packet, we can do a duplicate import and try to capture corrected data from NLM if they have it.
In PROD currently only 10 of the citations retrieved with %<%>% have been approved for full text review. 3 of which are legacy citations. 3 are using < and > for measurements in the title. Leaving only 4 citations with html markup. However, the markup is only showing in the Article Search retrieval list. When you click to see the Full Article History the title displays correctly so it may display in the packets correctly as well.
Verified on QA. Thanks!
| File Name | Posted | User |
|---|---|---|
| image-2023-01-23-14-15-11-171.png | 2023-01-23 14:15:14 | Kline, Bob (NIH/NCI) [C] |
Elapsed: 0:00:00.000527