CDR Tickets
| Issue Number | 4354 |
|---|---|
| Summary | Scheduler submits Job twice |
| Created | 2017-12-20 11:22:22 |
| Issue Type | Bug |
| Submitted By | Englisch, Volker (NIH/NCI) [C] |
| Assigned To | Kline, Bob (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2018-10-18 14:05:56 |
| Resolution | Won't Fix |
| Path | /home/bkline/backups/jira/ocecdr/issue.218671 |
On occasion, when we submit a publishing job manually via the scheduler interface that job is submitted twice.
This problem doesn't seem to be happening every time one submits a job via the scheduler. When a nightly publishing job is submitted, for instance, the publishing job starts but a few seconds or maybe minutes that same job is submitted again. In the case of a publishing job the second job fails immediately with a message that a job is currently running. This is expected behavior but the second job shouldn't be submitted at all.
Here is the log for the last time the problem showed up:
=========== Opening Log ===========
TIER: STAGE DATETIME: Mon Dec 18 15:26:57 2017
!2888: Mon Dec 18 15:26:57 2017: SubmitPubJob - Started
!2888: Mon Dec 18 15:26:57 2017: Arguments: ['D:/cdr/publishing/SubmitPubJob.py', '--live', '--interim']
!2888: Mon Dec 18 15:26:57 2017: running in LIVE mode
!2888: Mon Dec 18 15:26:57 2017: running in INTERIM mode
!2888: Mon Dec 18 15:26:57 2017: Checking job queue ...
!2888: Mon Dec 18 15:26:58 2017: OK to submit
!2888: Mon Dec 18 15:26:58 2017: Submitting publishing job...
!2888: Mon Dec 18 15:27:01 2017: Pub job started as Job15972
!2888: Mon Dec 18 15:27:01 2017: Waiting for publishing job to complete...
=========== Opening Log ===========
TIER: STAGE DATETIME: Mon Dec 18 15:33:17 2017
!3044: Mon Dec 18 15:33:17 2017: SubmitPubJob - Started
!3044: Mon Dec 18 15:33:17 2017: Arguments: ['D:/cdr/publishing/SubmitPubJob.py', '--live', '--interim']
!3044: Mon Dec 18 15:33:17 2017: running in LIVE mode
!3044: Mon Dec 18 15:33:17 2017: running in INTERIM mode
!3044: Mon Dec 18 15:33:17 2017: Checking job queue ...
!3044: Mon Dec 18 15:33:17 2017:
Interim-Export job is still running.
!3044: Mon Dec 18 15:33:17 2017: Job15972 status: In process
!3044: Mon Dec 18 15:33:17 2017: Job15972 type : Interim-Export
!3044: Mon Dec 18 15:33:17 2017: *** Standard Failure - Job15972 still in process (Interim-Export: In process)
Traceback follows:
Traceback (most recent call last):
File "D:/cdr/publishing/SubmitPubJob.py", line 322, in <module>
(currentJobs[0], pubSubset, currentJobs[2]))
Exception: Job15972 still in process (Interim-Export: In process)
Mon Dec 18 15:33:17 2017
=========== Closing Log ===========
!2888: Mon Dec 18 15:42:03 2017: Status: In process (900 sec)
!2888: Mon Dec 18 15:51:05 2017: Publishing job started at 2017-12-18 15:26:58
!2888: Mon Dec 18 15:51:05 2017: and completed at 2017-12-18 15:50:33
!2888: Mon Dec 18 15:51:20 2017: Push job started as Job15973
!2888: Mon Dec 18 15:53:20 2017: Pushing job started at 2017-12-18 15:50:33
!2888: Mon Dec 18 15:53:20 2017: and completed at 2017-12-18 15:52:43
!2888: Mon Dec 18 15:53:20 2017: Submitting Email: OK
Mon Dec 18 15:53:20 2017
=========== Closing Log ===========I started a nightly publishing job tonight on QA and ran into this issue again. The job was submitted at 18:25h and I received the following emails in my inbox - obviously from 2 publishing jobs:
18:25h: CBIIT-QA: Nightly Publishing Started
18:26h: CBIIT-QA: *** [CBIIT-QA] SubmitPubJob.py - Standard Failure
18:26h: CBIIT-QA: *** Error in SubmitPubJob.py
18:30h: CBIIT-QA: Status and Error Report for Nightly Publishing
18:30h: CBIIT-QA: Nightly Publishing Finished
Still happening?
Yes, I believe I've seen this once or twice on QA or DEV. I'd have to check the logs to say for sure.
Adding one more data point:
This week I repeatedly ran the scheduled job Glossary Translation
Job Notification via the Custom Run button of the
scheduler. None of those jobs were submitted twice. We may want to keep
this in mind and compare the differences between the weekly publishing
job and that Glossary Tranlation job.
Yes, I believe I've seen this once or twice on QA or DEV. I'd have to check the logs to say for sure.
Checking the logs on QA, I see a "still in process" error message on October 8, caused by a publishing job which didn't finish three days before and hadn't been marked with a failure status. The incident before that was on August 20, when Volker tried to start an interim update job manually with a push job still running. Prior to that we had a string of "still in process" errors in June caused by a stalled job which was left for several days without a terminal status. Pretty much the same thing in May when a push job got stalled in the "Verifying" state (presumably because of a Gatekeeper problem).
I also looked at the most recent "still in process" errors in the logs on DEV, and they also looked like they weren't caused by the scheduler.
You might want to go behind me, ~volker, to see if I'm mis-interpreting the log files.
Going through the logs I see the event happening on these days:
On STAGE
Wed Nov 29 10:19:44 2017
Mon Dec 18 15:26:57 2017
Mon Dec 18 16:01:20 2017
On QA
Wed Oct 25 12:38:45 2017
Mon Dec 04 18:02:13 2017
Thu Dec 14 18:12:34 2017
Tue Jan 2 13:17:52 2018
Wed Jan 10 17:36:11 2018
Tue Feb 13 10:35:43 2018
Thu Mar 1 18:18:55 2018
Mon Apr 2 18:44:29 2018
Fri Apr 6 10:21:29 2018
Mon Apr 16 18:36:21 2018
Mon Aug 20 10:43:20 2018
On DEV
Fri Jul 28 16:12:36 2017
Mon Sep 18 15:08:15 2017
Thu Oct 26 11:11:06 2017
Wed Jan 24 18:10:17 2018
Mon Apr 2 18:10:19 2018
Fri Apr 27 17:01:15 2018
Mon May 14 18:14:20 2018
Thu Jun 7 18:09:26 2018
Fri Jun 8 18:03:28 2018
Mon Aug 13 16:18:43 2018
Mon Aug 20 10:06:44 2018
Mon Oct 1 13:03:09 2018
It is correct that we cannot identify from looking at the logs alone if a job had been submitted a second time by one of us or if the second submission was a "scheduler problem". However, I am 100% certain that at least 90% of the events above were caused by manually submitting a publishing job via the scheduler.
Honing in more closely on the problem, I created a tool which aggregates relevant entries from several logs, adjusted time stamp formats and time zones (IIE logs using Zulu time and a non-ISO format), and sorted the entries. Here's what I see for yesterday.
2018-10-16 11:30:09.377 [INFO] nightly publishing task started (How
did this happen? (1))
2018-10-16 11:30:10 JOB16736 CREATED (interim-export created by the task
started a second earlier)
2018-10-16 11:37:17 JOB16737 CREATED (push job for 16736)
2018-10-16 11:39:26-04:00 volker 10.133.9.220 Publishing Job Nightly
(custom run from scheduler (2))
2018-10-16 11:47:17 JOB16738 CREATED (republish export job (3))
2018-10-16 11:53:14 JOB16739 CREATED (push job for 16738 - failed
because of GK error)
2018-10-16 11:55:25 JOB16740 CREATED (republish export job - also
failed)
2018-10-16 12:03:01.285 [INFO] nightly publishing task started (again,
how?)
2018-10-16 12:03:02 Job16739 STILL IN PROGRESS
2018-10-16 12:03:03-04:00 volker 10.133.9.220 Publishing Job
Nightly
2018-10-16 12:05:27.073 [INFO] nightly publishing task started
2018-10-16 12:05:28 JOB16741 CREATED
2018-10-16 12:11:16 JOB16742 CREATED
2018-10-16 12:12:44-04:00 volker 10.133.9.220 Publishing Job
Nightly
2018-10-16 17:21:25-04:00 bkline 10.133.190.1 Emailer Tracking
Update
2018-10-16 18:05:00.096 [INFO] nightly publishing task started
2018-10-16 18:05:01 JOB16743 CREATED
2018-10-16 18:14:08 JOB16744 CREATED
(1) This job is regularly scheduled to run at 18:05 Monday through
Thursday, and there is no log by IIS of a request to run it from the web
scheduler admin interface until more than nine minutes later.
(2) The job which was created eight minutes later is not the nightly
export job, but according to IIS, Volker didn't tell the scheduler to
run the nightly publishing job until after the push job (16737) had
finished.
(3) Presumably requested from the web publishing admin interface.
Ah-hah! IIS doesn't log the date/time it received the request, but the time it finished. Looks like there's a milliseconds-elapsed field I should be able to use to calculate when the request was received.
This is more like it. Here's yesterday's aggregated/processed logs:
2018-10-16 11:30:08 volker 10.133.9.220 Publishing Job Nightly (557857 ms)
2018-10-16 11:30:09 nightly publishing task started
2018-10-16 11:30:10 Interim-Export Job 16736 started (Success)
2018-10-16 11:37:17 Push_Documents_To_Cancer.Gov_Interim-Export Job 16737 started (Success)
2018-10-16 11:47:17 Republish-Export Job 16738 started (Success)
2018-10-16 11:53:14 Push_Documents_To_Cancer.Gov_Republish-Export Job 16739 started (Failure)
2018-10-16 11:55:25 Republish-Export Job 16740 started (Failure)
2018-10-16 12:03:00 volker 10.133.9.220 Publishing Job Nightly (2775 ms)
2018-10-16 12:03:01 nightly publishing task started
2018-10-16 12:03:02 Job16739 *** STILL IN PROGRESS ***
2018-10-16 12:05:25 volker 10.133.9.220 Publishing Job Nightly (438378 ms)
2018-10-16 12:05:27 nightly publishing task started
2018-10-16 12:05:28 Interim-Export Job 16741 started (Success)
2018-10-16 12:11:16 Push_Documents_To_Cancer.Gov_Interim-Export Job 16742 started (Success)
2018-10-16 17:21:23 bkline 10.133.190.1 Emailer Tracking Update (1456 ms)
2018-10-16 18:05:00 nightly publishing task started
2018-10-16 18:05:01 Interim-Export Job 16743 started (Success)
2018-10-16 18:14:08 Push_Documents_To_Cancer.Gov_Interim-Export Job 16744 started (Success)So this STILL IN PROGRESS message looks much less
suspicious than it did when the log message lines were not in the right
sequence. According to push-job-verifier.log, job 16739
wasn't marked as having failed until 12:05, so it would be correct that
the request to kick off the nightly publishing job manually from the
scheduler would be rejected. I will go back and perform similar analysis
on the earlier STILL IN PROGRESS messages.
Going back to the 1st of this month, things look more suspicious.
2018-10-01 12:53:27 volker 10.133.9.220 Publishing Job Weekly (completed 12:53:40) (web request)
2018-10-01 12:53:30 weekly publishing task started (scheduler task logs its start)
2018-10-01 12:53:36 Job16708 *** STILL IN PROGRESS *** (correctly notices that the previous day's job is still unresolved)
2018-10-01 13:03:08 weekly publishing task started (*** WHERE DID THIS COME FROM? ***)
2018-10-01 13:03:09 Export Job 16709 started (Success)
2018-10-01 13:09:17 volker 10.133.9.220 Publishing Job Weekly (completed 13:09:21)
2018-10-01 13:09:18 weekly publishing task started
2018-10-01 13:09:20 Job16709 *** STILL IN PROGRESS ***
2018-10-01 13:20:17 Push_Documents_To_Cancer.Gov_Export Job 16710 started (Success)
2018-10-01 18:05:00 nightly publishing task started (our regularly scheduled show)
2018-10-01 18:05:02 Interim-Export Job 16711 started (Success)
2018-10-01 18:13:16 Push_Documents_To_Cancer.Gov_Interim-Export Job 16712 started (Success)So in this case, Volker submitted one request via the web scheduler
admin interface at 12:53:27, and as far as I can tell that resulted in
invoking PublishingTask.Perform() twice: once at 12:53:30
(as expected) and a second time approximately 10 minutes later. This
isn't exactly the condition reported by this ticket, because the first
invocation of PublishingTask.Perform() failed (correctly)
and the second invocation succeeded, whereas this ticket is reporting
instances in which the first invocation succeeds and the second
invocation fails because of the job(s) created by the first invocation.
It's conceivable (but hard to verify, given the very thin documentation
we're dealing with for the underlying ndscheduler package)
that the scheduler is adding some resilience, recognizing that the first
attempt failed, and is trying again. Let's give it the benefit of the
doubt (particularly since in this case the behavior resulted in a
desirable outcome) and I'll keep walking backwards through the logs,
continuing this analysis.
This isn't exactly the condition reported by this ticket,
This is exactly the situation reported if you
consider the job started at 13:03h as the one starting two jobs. The job
submission on 12:53h is not related to the one at 13:03h. The two jobs
starting at 13:03h and 13:09h are the related ones.
The job starting on 18:05h is the regular nightly publishing job
unrelated to the two running around 1pm.
My understanding of what you were reporting in the original
description for this ticket was (paraphrasing): "I click the button in
the web scheduler admin interface to run a job by hand and the request
is sometimes processed twice." In the log entries above, the ones that
say
volker 10.133.9.220 Publishing Job Weekly (completed ....)
are the ones which represent the "I click the button ..." part. So you
clicked that button twice on October 1st: once at 12:53 and once at
1:09. The entries which say
nightly|weekly publishing task started represent the first
logging entry created by the scheduled task's class when its
Perform() method is invoked. This happened four times on
that day: twice as a result of your first manual request from the web
(once a few seconds after you clicked the button and a second time about
ten minutes later), once in response to your second manual job request
(a second after you clicked the button), and once for the nightly
scheduled job at 6:05pm, unrelated to any manual web page clicks.
So the two invocations you're saying are related (13:03 and 13:09) are actually in response to two different events on the scheduler web page. Does this make sense? To simplify the log entries further:
12:53 - first "run" click on the web page
12:53 - first invocation of the weekly publishing task (failed)
13:03 - second invocation of the weekly publishing task (succeeded)
13:09 - second "run" click on the web page
13:09 - third invocation of the weekly publishing task (failed, 13:03 job still running)
18:05 - invocation of the nightly publishing task (scheduled, no "run" click needed)If this is still muddy, we can walk through it on the white board together tomorrow.
In my opinion, the text for 13:03 and 13:09 should be swapped because:
I submit a job via the scheduler
The job fails because the previous job is still running
I manually fail the job still running (this is not captured in the log file)
I submit a job again via the scheduler (this job will succeed)
The scheduler submits a second job (this job will fail)
The nightly publishing job is starting
While reading your comment I was wondering about the following possible scenario: Is it possible that the "double-submission" only appears after a previously failed job? I'll have to double-check the logs for this.
Yes, let's use a white board to discuss the scenarios.
In my opinion, the text for 13:03 and 13:09 should be swapped because: ...
You might wish things had happened in such a way that the descriptions could be swapped, but that's not what actually happened. In your fourth bullet you have "I submit a job again via the scheduler (this job will succeed)" but the job which succeeded was created six minutes before you "submit the job again via the scheduler." No?
I'm beginning to get a somewhat clearer picture of at least part of
what's going on. For a successful weekly publishing job (and maybe for a
nightly publishing job, but that's less likely), the processing takes
too long for IIS to wait for completion when the job is requested
manually from the scheduler's web admin interface. So as it turns out,
there were actually three clicks on the Run button on
October 1, not two clicks. The second click didn't ever get recorded in
the IIS logs, because by the time the job completed successfully, IIS
had given up. We would probably have seen a record of this in the error
logs for a normal web server, but CBIIT has error logging turned off for
IIS. We do have evidence for all three requests, however, in our proxy
log, which captures quite a bit of information. In the screen shot below
you can see the proxy log entries on the left and the logs from the
scheduler's implementation of the publishing task on the right. In the
proxy log window, the lines which say "Performing 'POST' request ..."
are recorded when the request is handed off to the scheduler on port
8888. There are three such lines for the 1st of October. The lines which
say "POST /api/v1/executions/..." are recorded when control is returned
to the web server and its CGI scripts (and right before the script ends
and IIS records the request in the access log). That line is missing for
the second POST request, because IIS has abandoned the thread on which
the request was being processed. But you can see from the logs on the
right side that the publishing job runs to completion (see the arrow
running down the right side). IIS can walk away from the request, but it
has no way to stop the scheduler from completing the work it was given
to do. In any case, all of the requests were handled properly by the
scheduler on October 1st. I will continue going back through the logs to
try and find when we had the most recent instance of the condition
reported by this ticket.
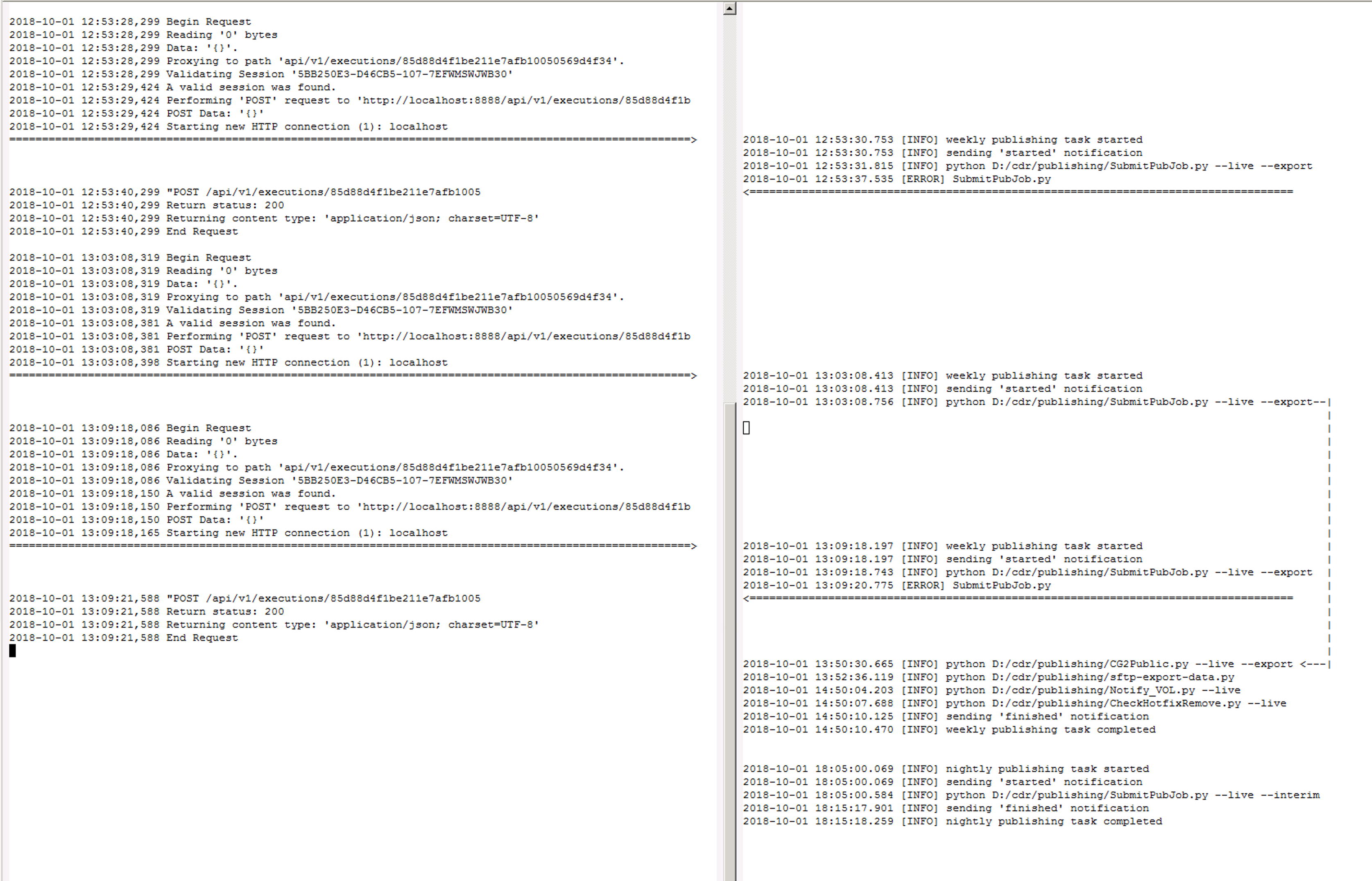
Learning more about the vagaries of the logging performed by IIS. On August 20, there were two POST requests from the scheduler's web admin page for a nightly publishing job, one submitted at 10:06:43 (finishing at 10:15:01) and the other submitted at 10:12:52 (finishing at 10:12:55). Only the second request was recorded in the IIS access logs, though the proxy log has a full set of log entries for both requests (including the "End Request" log message recorded right before IIS gets control back and should presumably be recording the request in the access log). This case comes closest to the behavior reported by this ticket. The first manual request from the web browser created a nightly publishing job which completed successfully. The second manual request was rejected because of the ongoing job created by the first request. The odd bit about this case is that IIS did not record the first request. There are multiple possible interpretations of the data for this day.
The user (Volker, in this case) clicked the "Run" button twice, once at 10:06:43 and once at 10:12:52. We don't know why IIS did not record the first click.
The user only clicked the "Run" button once, at 10:06:43. The web server gets the request and hands it to the CGI script, which hands the request off to the scheduler service. The job runs successfully, control returns to the proxying CGI script, which completes its logging of the processing of the job and returns a success return code to IIS. In the meantime (some time before 10:12:52) the browser cancels the request for some unknown reason and sends it again. IIS does not log the first request, but for some reason does not stop the CGI script from continuing.
A variation of the previous explanation, but instead of the browser cancelling the request, the web server for some unknown reason loses track of the CGI script that it kicked off for the original request, and starts a second instance of the CGI script to handle the request, and records the request as having been submitted at the point when it launches the second instance of the CGI script.
None of these seems like very likely, compelling explanations but I don't have anything better right now. Going to reach out to ~bryanp and ~learnb to ask if they have any theories.
After spending a lot of time reviewing/analyzing the logs and discussing the behavior of the browser, the web server, and the scheduler with Bryan and Blair, we have concluded that it is not worth spending any more time on this ticket, as it doesn't happen very often, and (at least for the types of jobs for which we have seen the reported behavior) the effect is benign.
| File Name | Posted | User |
|---|---|---|
| Screenshot 2018-10-18 08.49.26.png | 2018-10-18 08:50:58 | Kline, Bob (NIH/NCI) [C] |
Elapsed: 0:00:00.000382