CDR Tickets
| Issue Number | 5007 |
|---|---|
| Summary | Include DocId in Show CDR Document XML report |
| Created | 2021-07-16 15:14:54 |
| Issue Type | Inquiry |
| Submitted By | Osei-Poku, William (NIH/NCI) [C] |
| Assigned To | Englisch, Volker (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2021-08-05 12:49:48 |
| Resolution | Won't Fix |
| Path | /home/bkline/backups/jira/ocecdr/issue.294364 |
It will be nice to include the CDR ID (Doc_ID) in the XML of the "Show CDR Document XML" report. It is not a big deal but a nice thing to have.
I have sometimes wished for that myself, and then I realize why we don't do it. The problem with doing that is that this report is sending the document's raw XML to the browser as an XML document, not as a marked-up HTML document. This allows you to take advantage of the browser's built-in features for display of XML documents, including
color highlighting of element tags and attributes
hierarchical indenting of the nested elements
the ability to collapse and expand portions of the document
showing unescaped HTML entities (for example, "&" instead of "&")
The script could modify the document, adding an attribute for the ID, but then you wouldn't be getting the document exactly as it's stored in the CDR, and the way we're doing it now means this script can be used in a pipeline to be consumed by tools which need the CDR document itself, not a modified version of the document.
We could undertake a project to modify the schemas for all of the document types, adding an attribute to the top-level elements for the document ID, rewrite the core document-save software on the server, and run a global change to update all of the documents on all of the tiers, but that would be an expensive way to get the ID which you already have in the URL showing in the address bar of your browser.
I agree that it would be nice to include the CDR-ID in the XML but it would be wrong to do so.
The report is listing the XML of the document stored in the database that is specified based on the options. You may have noticed that the report type "Filtered XML most recently sent to cancer.gov" does include the CDR-ID as an attribute of the root element. The ID is included because that is what the document looks like after the filter process..
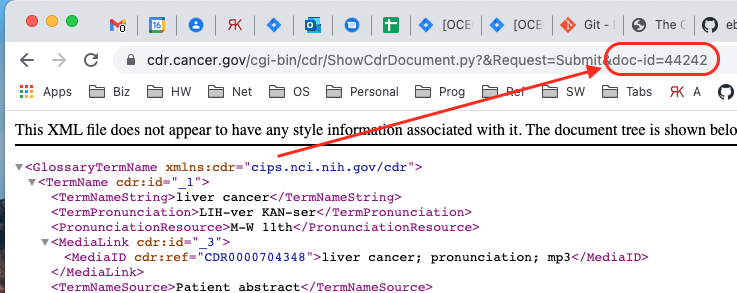
A work-around to identify which document you are looking at would be
to look for the "doc-id" parameter in the URL:
https://cdr-dev.cancer.gov/cgi-bin/cdr/ShowCdrDocument.py?Session=guest&Request=Submit&selection_method=id&version=&vtype=cwd&*doc-id=62902*
**If this is not sufficient we can probably create some kind of a report header and display the displayed XML underneath but we certainly don't want to add the CDR-ID to the XML if it's not part of the document already. I will need to discuss the report output with ~bkline. We would likely loose the colored and indented formatting of the XML if we're trying to combine an HTML header with a XML body.
We would likely loose the colored and indented formatting of the XML ...
We would definitely lose that formatting and the ability to collapse and expand portions of the document.
We decided not to proceed with this modification. Closing this ticket.
| File Name | Posted | User |
|---|---|---|
| image-2021-07-16-15-46-26-279.png | 2021-07-16 15:46:27 | Kline, Bob (NIH/NCI) [C] |
Elapsed: 0:00:00.000778