CDR Tickets
| Issue Number | 4568 |
|---|---|
| Summary | Standard Wording Report |
| Created | 2019-01-31 12:45:30 |
| Issue Type | Improvement |
| Submitted By | Osei-Poku, William (NIH/NCI) [C] |
| Assigned To | Kline, Bob (NIH/NCI) [C] |
| Status | Closed |
| Resolved | 2019-08-09 13:06:49 |
| Resolution | Fixed |
| Path | /home/bkline/backups/jira/ocecdr/issue.239464 |
This ticket is for a new report to help with Standard Wording projects. It is replaces OCECDR-4501. I have attached one of the the specification documents. I will attach a mock-up of the spreadsheet soon.
Looking at your document description I don't completely understand every desired feature.
Ability to search every part o a summary, including data in the following ...
Are you saying you don't want to limit the search at all or you only want to search within Para, GlossaryTermName, ItemizedList, etc.?
I don't understand what you consider "Free text".Ability to search multiple terms
Could you describe how you would like to search using multiple terms? You're entering Standard Wording substrings here, right? How would you separate those by spaces or commas?OK
OK
OK
OK
OK
OK
Regarding 4-8 I'm assuming you're looking for an interface similar to the "Summaries Type of Changes" report.OK
OK
Would you be able to define the meaning of "show the surrounding text of the term or phrase"? Should this be a fixed number of characters, words, sentences or maybe variable amount of text like "include entire sentence, paragraph, etc"? Would the amount of text to show be identified by the user?
"Show if the term is a glossary or not".
Could you provide a use case how the report would be used here?Same as above.
"Show the sections that the term(s) are in."
What type of information would you like to be displayed? Isn't this very similar to item (11)?
Adding a mock up or sample of expected search results. Mock-Up of Desired SW Report Results - Excel Spreadsheet.xlsx
Looking at your document description I don't completely understand every desired feature.
Ability to search every part of a summary, including data in the following ...
Are you saying you don't want to limit the search at all or you only want to search within Para, GlossaryTermName, ItemizedList, etc.?
I don't understand what you consider "Free text".
The list of elements are where we expect to find the data we will be looking for but we wanted to make sure that text data in the body of the summary is included in the search. Thus the use of "Free text". Please ignore that.
2. Ability to search multiple terms
Could you describe how you would like to search using multiple terms? You're entering Standard Wording substrings here, right? How would you separate those by spaces or commas?
We would like to separate them by commas.
Regarding 4-8 I'm assuming you're looking for an interface similar to the "Summaries Type of Changes" report.
Yes, this is right.
11. Would you be able to define the meaning of "show the surrounding text of the term or phrase"? Should this be a fixed number of characters, words, sentences or maybe variable amount of text like "include entire sentence, paragraph, etc"? Would the amount of text to show be identified by the user?
The surrounding text should be of a reasonable amount for the user to read the text from the report to make a decision so we would go with a paragraph. This should be set by the program not the user.
12. "Show if the term is a glossary or not".
Could you provide a use case how the report would be used here?
Some of the standard wording terms are glossary terms and some are not. I think most of them are glossary terms. Knowing which ones are or which ones are not glossary terms is all we wanted to know.
13. Same as above 🙂.
14. "Show the sections that the term(s) are in."
What type of information would you like to be displayed? Isn't this very similar to item (11)?
Identifying and displaying the section title should be enough for this requirement.
~volker We have a major project coming up in the next few weeks that this report would be very helpful to use. Wondering if it is possible to get the report done up to QA? We can use it on QA with fresh PROD data. If this is possible, we can talk about it in the CDR meeting this Thursday.
This is not a simple report and I'm working on a different project at the moment. I don't know how much time I would be able to spend to create this report and how long it would take to finish.
14. "Show the sections that the term(s) are in."
What type of information would you like to be displayed? Isn't this
very similar to item (11)?
Identifying and displaying the section title should be enough for this requirement.
Looking at your sample spreadsheet it appears you want the top-level SummarySection Title element displayed. Please let me know if you're expecting something different.
I'm still trying to understand item (1) of your requirements:
Ability to search every part of a summary, including data in the
following: Para tags, Glossary tags, KeyPoints, ...
Do you need the ability to limit the search to just one or multiple of these listed elements or is the goal to find the specified terms within the document regardless of where they appear?
I don't see any indication in your sample spreadsheet output where the specific element where the term was found is needed except for the specification of the glossary term or StandardWording elements.
Yes, the goal is to find the search terms anywhere in the document. The list of elements are typically where we would find the terms. However, please don't limit the search to these terms if they could be found elsewhere in a document.
Please clarify item (4):
Exclude blocked summaries from report
Are you asking to always exclude blocked documents or do you want the option to exclude blocked summaries?
Blocked summaries should be excluded by default. Also, having the option to include blocked summaries in the search would be fine. Thanks!
So, you're answer is you do want the option to exclude (or include if exclusion is the default) blocked documents.
That right. Thanks!
Another one for which you're in a better position to come up with an estimate, ~volker.
Yes, what you assume is correct about this. Thanks!
Question regarding request #11:
Ability to show the surrounding text of the term or phrase.
What do you expect to have included in the surrounding text? Comments, CitationLinks, markup, elements?
The surrounding text should be a few words before and after the selected search term. It could also be a paragraph with the selected search term highlighted so that it would be easy to identify.
Here is an example:
Assume the text phrase we're looking for is PDQ and
we're including 5 words before and after the phrase. The paragraph we're
looking at is the following:
<Para>Carcinoid tumors of the small intestine are covered
elsewhere as a separate cancer entity. (Refer to the PDQ summary on
<SummaryRef cdr:href="CDR0000062893">Gastrointestinal Carcinoid
Tumor Treatment</SummaryRef> for more
information.)</Para>
We may decide to only include Para-text:
"... cancer entity. (Refer to the PDQ summary on for more
information..."
We may decide to include any text excluding element tags:
"... cancer entity. (Refer to the PDQ summary on Gastrointestinal
Carcinoid Tumor..."
We may decide to include all text including element tags, attributes,
etc:
"... cancer entity. (Refer to the PDQ summary on
<SummaryRef>Gastrointestinal Carcinoid..."
Please keep in mind that the SummaryRef could also be a Comment,
CitationLink, SectMetaData, etc.
I understand what you are looking for in principle but for the program we'll need to make a decision so that everyone will know how to use the report. The users won't be able to copy/paste the presented text and expect to find the correct location of the phrase.
Please include only the para text. There is no need to include other elements. The main purpose of the surrounding text is to enable users know the context in which the term is mentioned so that they can decide whether to make changes or not.
More questions regarding your report:
On your sample spreadsheet you have these two column headings, "Inside
Glossary Term Ref Tags (Y/N)" and "Inside SW Tags (Y/N)". I am assuming
that the word Inside has a different meaning for the glossaries
and standard wording. My assumption is that you mark the Standard
Wording flag if the search string is contained within
the StandardWording element, i.e. if it's a substring of the
StandardWording. For the glossaries, however, we're only marking the
flag if the search term is identical to the search term
as discussed in our meeting yesterday. Searching for "cancer" will not
set the glossary flag when "breast cancer" or "cancer treatment" is
found.
Yes, your assumptions are correct. Thanks!
For the report to run on the upper tiers (STAGE, PROD) the library
xslxwriter will have to be installed. We will need to submit a
CBIIT ticket to do so.
The installation script is located at
\\nciis-p401.nci.nih.gov\cdr_deployments\install-xlsxwriter.cmdAdding these additional requirements from ~oseipokuw from an email exchange, so that I won't forget:
When we search for a term, can you also search for the variants automatically? At the moment, when we search for a term, we have to include the variants for the results to include all of them. If the variants can be included automatically when we search for the major terms, that would be great.
Can the summary title be listed only once instead of multiple times? I will provide a sample and explain further.
Both of the newly requested options have been implemented on QA. I've used the glossary term and variants of diagnosis and radiation therapy for testing.
Please have a look.
It looks like when you search for a term, "lymph node", for example, the variants are retrieved and displayed in the Matching Phrase column and a surrounding text column. However, the original term is not retrieved or displayed. Meanwhile, when you search with a variant, for example, "biopsies" or "lymph nodes", you get the following error message: "too many values to unpack"
It looks like when you search for a term, "lymph node", for example, the variants are retrieved and displayed in the Matching Phrase column and a surrounding text column. However, the original term is not retrieved or displayed.
Yes and this is the correct behavior. The previous version evaluated
the strings the user entered and displayed those entered phrases as-is
in the column Matching Phrase. The new version does the same
with the only difference that the user isn't manually entering all of
the variants you're searching for but all of the variants are
automatically entered. I am wondering if you were expecting the actual
glossary term to be displayed in the Matching Phrase column. If I
entered the term lymph node which gets displayed in the
Matching Phrase column but see the variant supraclavicular
lymph nodes displayed in the Surrounding Test column I
would I would get confused when those don't match up.
Similarly, you're expecting the entered term to be displayed in the
Matching Phrase column even though it's not a glossary term,
nor a variant term. If you're expecting only glossary terms or variants
to be displayed in the Matching Phrase column we would need to
leave that field blank in those cases. This would be kind of strange as
well when you're displaying matching text in the Surrounding
Text column but not the Matching Phrase column.
Meanwhile, when you search with a variant, for example, "biopsies" or "lymph nodes", you get the following error message: "too many values to unpack"
If this is not a bug we may be reaching a technical limit here with
the way the report has bee written and it might mean the report needs to
be redone. I'll have to look into this more deeply.
Could you please give me the input values you're using?
If this is not a bug we may be reaching a technical limit here with the way the report has bee written and it might mean the report needs to be redone. I'll have to look into this more deeply.
Could you please give me the input values you're using?
I only enter the search term with all everything else remains the default.
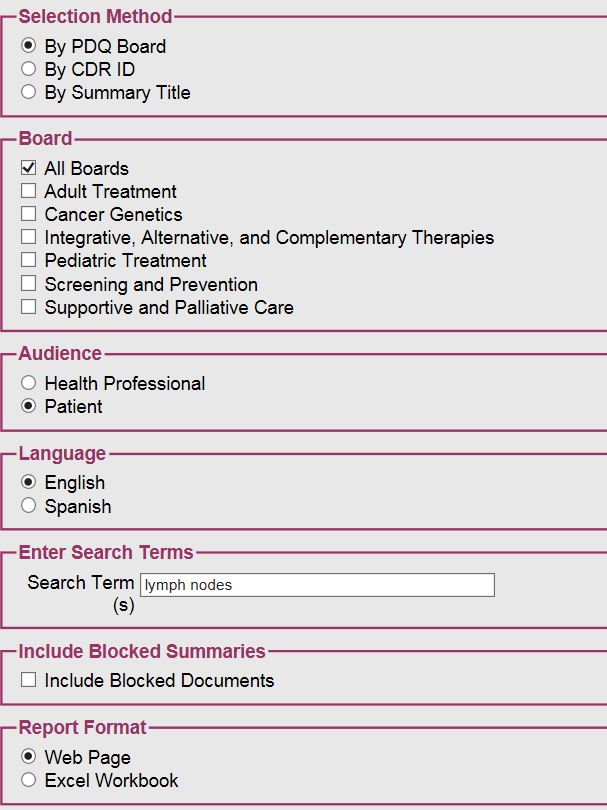
I am wondering if you were expecting the actual glossary term to be displayed in the Matching Phrase column. If I entered the term lymph node which gets displayed in the _Matching Phrase_column but see the variant supraclavicular lymph nodes displayed in the Surrounding Test column I would I would get confused when those don't match up.
I understand your reasoning for not including the variants in the Matching Phrase column. So, let's keep it as is.
However, it would be helpful to also display and bold both the glossary term and the variants in the Surrounding Text field, if that is possible.
However, it would be helpful to also display and bold both the glossary term and the variants in the Surrounding Text field, if that is possible.
Could you provide a sample of how that would look like?
Bump.
I realize this is late in the game, but there seem to be some loose requirements not nailed down above. If I've missed some clarifications in the previous comments, I apologize.
3. Ability to find a phrase even if part of it is in glossary tags and part is not in glossary tags ...
12. Ability to show if the term is a glossary term or not.
13. Ability to show if the term is in Standard Wording tags or not
If the software is looking for a given phrase, and part of the phrase is found inside glossary tags and part is outside those tags, then the report will show the phrase as not a glossary term.
Even with that understanding of requirement #12, this combination of requirements presents a fairly complex processing problem. In order to implement them correctly, the report software will need to perform many passes through each summary.
FOR EACH SUMMARY
FOR EACH TOP-LEVEL SUMMARY SECTION
FOR EACH GLOSSARY TERM IN THE SECTION
FOR EACH SEARCH PHRASE
IF THE TERM MATCHES THE PHRASE
FIND OUT IF THE TERM IS IN A STANDARD WORDING BLOCK
FETCH THE PRECEDING AND FOLLOWING TEXT FOR CONTEXT
ADD A ROW TO THE REPORT (GT=YES, SW=YES|NO)
MASK OUT THE GLOSSARY TERM SO IT WON'T BE FOUND IN A SUBSEQUENT PASS
FOR EACH STANDARD WORDING BLOCK IN THE SECTION
EXTRACT THE BLOCK'S TEXT WITH MARKUP STRIPPED
FOR EACH SEARCH PHRASE
FOR EACH MATCH WITH THE PHRASE FOUND IN THE EXTRACTED TEXT
FETCH THE PRECEDING AND FOLLOWING TEXT FOR CONTEXT
ADD A ROW TO THE REPORT (GT=NO SW=YES)
MASK OUT THE MATCHED PHRASE SO IT WON'T BE FOUND IN A SUBSEQUENT PASS
REPLACE THE STANDARD WORDING BLOCK'S CONTENT WITH THE EXTRACTED MASKED TEXT
PRESERVE ANY TAIL TEXT FOR THAT BLOCK
EXTRACT THE SECTION'S TEXT WITH MARKUP STRIPPED
FOR EACH SEARCH PHRASE
FOR EACH MATCH WITH THE PHRASE FOUND IN THE EXTRACTED TEXT
ADD A ROW TO THE REPORT (GT=NO SW=NO)Even that level of complexity ignores some edge cases. If you wanted to avoid presenting false hits when the beginning of a search phrase appears at the end of one paragraph and the end of the phrase starts the next paragraph (or worse, different subsections), you would need that last loop broken up to — at the very least — walk separately through each subsection, if not more granular loops through a specified set of elements (e.g., paragraph, list item, table cell, etc.). Or we could take William's comment above literally (after confirming that this is what he really meant):
Please include only the para text. There is no need to include other elements.
That would mean we'd ignore matches in tables or lists. I'm not convinced yet that this was William's intention when he wrote that.
I gather that glossary term variant matching has been added to the
original requirements set out in the Word document, so
SEARCH PHRASE in the pseudo-code logic above actually
refers to the exploded list of phrases generated based on the search
terms provided by the user. It is probably a good idea to sort that
exploded list by length, with the longest strings first, the way we do
in the glossifier. By the way, I see that William has asked that the
phrases be delimited by the comma character. You realize that this would
mean that you can't search for glossary terms which have commas in them
(as many do), right?
The original requirements call for the ability to use wildcards. How is this supported? Are we using regular expressions? Or was that requirement dropped?
Note that fetching the preceding and following text for context in the case of glossary terms and standard wording blocks is not a simple as finding an enclosing ancestor element, extracting all of the text without markup, and locating the target phrase in that extracted text, because if the phrase occurs more than once in the surrounding block, once with and once without glossary (or standard wording) markup, it is impossible to tell in the extracted text which occurrence is the one with the glossary (or standard wording) markup. So instead the software has to very carefully walk backwards and forwards with sibling nodes (and parent nodes if siblings don't provide enough context) until sufficient context is obtained.
Also, we need to be careful when we mask out matches so they won't be found in subsequent passes to use unique placeholders which map back to the masked out original text, because that original text may be needed as surrounding context for other matched phrases in the same vicinity.
Very tricky report! At least 20 points, if not
more. 😛 It would be an 8 or a 13 if the requirement to match phrases
which straddle GlossaryTermRef elements (with part of the
target phrase inside the element and part hanging outside) were dropped.
I would be curious to know what the use case is for this particular
requirement. What purpose does it serve?
Also, it would be good to be explicit in the requirements about how
Insertion and Deletion markup is handled, so
we don't have misunderstandings similar to those which arose for
OCECDR-4587.
One more note: be sure to use regular expressions to enforce word boundaries, so we don't end up with bogus matches (for example, "finding" breast in walking abreast).
Even that level of complexity ignores some edge cases. If you wanted to avoid presenting false hits when the beginning of a search phrase appears at the end of one paragraph and the end of the phrase starts the next paragraph (or worse, different subsections), you would need that last loop broken up to — at the very least — walk separately through each subsection, if not more granular loops through a specified set of elements (e.g., paragraph, list item, table cell, etc.). Or we could take William's comment above literally (after confirming that this is what he really meant):
Please include only the para text. There is no need to include other elements.
That would mean we'd ignore matches in tables or lists. I'm not convinced yet that this was William's intention when he wrote that.
{quote}
I just wanted to clarify that the comment you quoted above was in reference to a clarification of Requirement #11 and not Requirement #12.
11. Ability to show the surrounding text of the term or phrase.
The original requirement asked for the ability to identify terms in itemized lists.
Thanks, that's helpful.
Can you explain the purpose of the requirement to find phrases which
have one leg inside GlossaryTermRef markup and the rest of
the phrase outside of the element?
Can you confirm that it's OK that users won't be able to look for a phrase which has a comma in it?
Can you confirm that the requirement for searching for terms with wildcards has been dropped?
Is it OK if the software drops all Insertion blocks and
strips Deletion tags before processing the document?
Thanks.
Thanks, that's helpful.
Actually, on second reading, I'm still not sure what's being asked for, because although "Please include only the para text" wasn't marked as a quote, I don't think you were actually providing that as a fresh clarification of the requirements, but as part of what you were quoting.
The original requirement asked for the ability to identify terms in itemized lists.
Which of the following reflects what you intended to convey?
We originally wanted to include itemized lists in the portion of the document to be searched, but the requirements have changed and only terms found in
Paraelements should be reported.The original requirement asked for the ability to identify terms in itemized lists. That requirement has not changed, but we only want surrounding context to be provided for matches which were found in
Paraelements.
In either case, can you confirm that "include only the para text"
meant the text of the Para element and of all of its
descendants?
Assuming that's true, I propose that the software strip the tags (but not the text) for the following list of elements.
STRIP = (
"Caption",
"Deletion",
"Emphasis",
"ExternalRef",
"FigureNumber",
"ForeignWord",
"GeneName",
"GlossaryTermLink",
"InterventionName",
"LOERef",
"MediaID",
"MediaLink",
"Note",
"ProtocolLink",
"ProtocolRef",
"ReferencedFigureNumber",
"ReferencedTableNumber",
"ScientificName",
"Strong",
"Subscript",
"SummaryFragmentRef",
"SummaryRef",
"Superscript",
"TT",
)Does that match what you expect? Or should we strip the child elements and their text content? Or should we strip just the tags for some of these and strip the entire elements for others?
Can you explain the purpose of the requirement to find phrases which have one leg insideGlossaryTermRefmarkup and the rest of the phrase outside of the element?
Here is one example from the project we are currently working on. The search term is “cytogenetic analysis.” There’s currently not a glossary term for “cytogenetic analysis” but there is one for “cytogenetics.” So in the term, “cytogenetic” is glossified and “analysis” isn’t. We would still want to find all places that “cytogenetic analysis” is in summaries, even though “cytogenetic” is in glossary tags and “analysis” isn’t.
Can you confirm that it's OK that users won't be able to look for a phrase which has a comma in it?
Users would want to be able to look for a phrase with a comma in it. However, the impression I have is that users don't expect that many of the phrases have commas in them. Most of them if not all appear to be plurals of the glossary term. I can't say the same thing for the Spanish content though.
#2 is what we expect and yes, it does match what we expect. Thanks!
Here is one example from the project we are currently working on. The search term is “cytogenetic analysis.” There’s currently not a glossary term for “cytogenetic analysis” but there is one for “cytogenetics.” So in the term, “cytogenetic” is glossified and “analysis” isn’t. We would still want to find all places that “cytogenetic analysis” is in summaries, even though “cytogenetic” is in glossary tags and “analysis” isn’t.
Normally, the CDR reports on the longest match when searching for multiple strings. So, for example, when the glossifier finds "liver cancer treatment" it only reports the match for that full string, suppressing matches for "liver" and "cancer" and "treatment" and "liver cancer" and "cancer treatment" even if they are also present as search target candidates. You're saying you want a different behavior here, with separate rows for both "cytogenetic" and "cytogenetic analysis" if both strings are specified for the report? That would mean the masking described in the pseudo code above to prevent using the same string for multiple matches is wrong.
If we avoid that masking, you will get two rows for "cytogenetic" for the same occurrence, one marked as inside glossary term markup, and the other marked up as not glossary term markup, in addition to the match for "cytogenetic analysis" (also marked as not glossary term markup). Is that acceptable?
You're aware that if "cytogenetic analysis" appears in a paragraph, it is impossible to apply glossary markup to both "cytogenetic" and "cytogenetic analysis," right? You have to choose one or the other.
Users would want to be able to look for a phrase with a comma in it.
How would they do that, if the software uses comma as the delimiter between phrases, as you requested?
However, the impression I have is that users don't expect that many of the phrases have commas in them. Most of them if not all appear to be plurals of the glossary term. I can't say the same thing for the Spanish content though.
Well, there are 58 such term name strings in the glossary documents themselves on DEV, and that's not counting the variants from the mapping table. For example, wound, ostomy, and continence nurse would be treated as three separate search targets.
It would be helpful to search insertion markup because if it’s eventually going to be in the summary it will need the correct standard wording. However, it’s probably OK not to search deletion markup since it will likely be deleted from the summary.
OK, then we'll do the opposite of what I had proposed. We'll remove
the Deletion elements and strip the Insertion
tags.
I don't understand your comment, ~bkline.
~oseipokuw and I discussed this issue. There was a bug in the code that only searched for the variant terms and excluded the glossary terms. Since that issue has been resolved there's nothing else to do and a sample of a modified report isn't necessary.
If we avoid that masking, you will get two rows for "cytogenetic" for the same occurrence, one marked as inside glossary term markup, and the other marked up as not glossary term markup, in addition to the match for "cytogenetic analysis" (also marked as not glossary term markup). Is that acceptable?
Please do not avoid the masking. We probably just have to learn to search for these terms with this information in mind.
How would they do that, if the software uses comma as the delimiter between phrases, as you requested?
In that case, we can use spaces to separate the terms.
In that case, we can use spaces to separate the terms.
OK, so if the user enters "cytogenetic analysis" and the document has
<Para>This study uses <GlossaryTermRef ...>cytogenetic</GlossaryTermRef> analysis to determine ...</Para>then the report will contain two separate rows:
Match |
Glossary? |
|---|---|
Some Section Title - This study uses cytogenetic analysis to determine ... |
Yes |
Some Section Title - This study uses cytogenetic analysis to determine ... |
No |
Also, the software will only be using variants pulled from the mapping table for the individual words, not for an entire multi-word phrase.
Agreed?
Finally, the original requirement #12 says
Ability to show if the term is a glossary term or not.
Do you want to modify that to
Ability to show if the term is in a glossary term or not.
in order to have a "Yes" in the Glossary column for both rows reflecting
Section Title - blah blah blah colon cancer more blah blah |
Yes |
Section Title - blah blah blah colon cancer more blah blah |
Yes |
when the XML has
<Para> blah blah blah <GlossaryTermRef ...>colon cancer</GlossaryTermRef> more blah blah</Para>?
Would dropping the "Glossary" column allow the showing of "colon cancer" in one row possible? If this is possible, it is preferred to showing them on multiple rows.
Also, the software will only be using variants pulled from the mapping table for the individual words, not for an entire multi-word phrase.
Agreed?
Can you explain this further? Does it mean that if there is a multi-word phrase variant in the mapping table, it won't be included in the search result?
Yes, if "foo" is the term name and the mapping table has "foo bar" as a variant, I would pick that up. But if "foo bar" is the term name, and "bar foo" is in the variant table for that glossary term and the user enters "foo bar" in the report request form, and we're using space as the delimiter between terms on the form, then the software will look for "foo" in the summaries, and it will look for "bar" in the summaries, but not for "foo bar" or "bar foo" as units.
I think replacing comma with space as the delimiter to separate what the user types on the form into the search terms might be going in the opposite direction from what you want the report to do.
Would dropping the "Glossary" column allow the showing of "colon cancer" in one row possible? If this is possible, it is preferred to showing them on multiple rows.
Dropping the column which indicates whether the match is marked up would simplify the report dramatically. If you do that, and I implement a separate field on the report request form for each phrase the user wants to be matched, we can make sure that "colon cancer" gets reported in one row instead of two.
Sure, it is okay to drop the "Glossary" column.
OK, I've got a preliminary version working (HTML only) at https://cdr-qa.cancer.gov/cgi-bin/cdr/SummaryStandardWording.py. I'll work on the Excel format tomorrow (it will take some custom coding in order to be able to handle the rich text formatting in the fourth column).
Thanks! It seems to be working very well. We will do additional testing and let you know if we run into any problems.
The Excel version is working now as well. I still have a little more testing and code review to do, but I think it should be ready for CIAT to play with. Just a heads up that Volker plans on refreshing QA some time today, so I have put the report on DEV as well.
https://cdr-dev.cancer.gov/cgi-bin/cdr/SummaryStandardWording.py
Verified on DEV. Thanks!
I know this is William's requested reported but we have been testing it too and I think it's going to be really helpful to all of us! One request - could you please add "Health Professional" or "Patient" to the top of the report output to indicate which content was searched? Thanks!
Let's make that a Kepler enhancement.
Added OCECDR-4647
Verified on PROD. Thanks!
| File Name | Posted | User |
|---|---|---|
| Mock-Up of Desired SW Report Results - Excel Spreadsheet.xlsx | 2019-04-10 12:30:33 | Osei-Poku, William (NIH/NCI) [C] |
| StandardWordingError.JPG | 2019-07-22 15:54:06 | Osei-Poku, William (NIH/NCI) [C] |
| Standard Wording Report SPECIFICATIONS-Final.docx | 2019-01-31 12:43:29 | Osei-Poku, William (NIH/NCI) [C] |
Elapsed: 0:00:00.001281